
Nel panorama dell’intelligenza artificiale, il 2025 è stato un anno di svolta per l’hardware dedicato. Google ha annunciato l’Ironwood, la sua settima generazione di Tensor Processing Unit (TPU), progettata specificamente per l’inferenza AI, il processo che permette ai modelli di “pensare” e rispondere in tempo reale.
Amazon, dal canto suo, ha lanciato Trainium3, il suo primo chip AI su processo a 3 nanometri, ottimizzato per training e inferenza di modelli complessi come agenti AI e generazione video. Questi lanci non sono solo innovazioni tecniche: rappresentano una mossa strategica per sfidare il dominio di Nvidia, che controlla oltre l’80% del mercato dei chip AI. Con costi inferiori e maggiore efficienza energetica, le TPU e i chip AWS potrebbero erodere quote di mercato, spingendo le grandi tech verso una diversificazione dell’infrastruttura AI. In questo post, esploreremo le differenze tecniche, l’evoluzione storica, i target di utenza, le prospettive di mercato e i rischi per il colosso verde.
Qual è la differenza tra una GPU e una TPU?
Le GPU (Graphics Processing Unit) e le TPU (Tensor Processing Unit) sono entrambe acceleratori hardware per l’AI, ma differiscono radicalmente per design, ottimizzazione e uso pratico. Le GPU, nate per il rendering grafico (pensate ai videogiochi), sono processori paralleli versatili, adattati all’AI grazie a migliaia di core che gestiscono calcoli floating-point complessi. Nvidia domina qui con CUDA, un ecosistema software maturo che supporta framework come PyTorch e TensorFlow.
Le TPU, invece, sono ASIC (Application-Specific Integrated Circuits) custom di Google, progettati da zero per operazioni tensoriali, il cuore del machine learning, come moltiplicazioni di matrici in reti neurali. Non hanno overhead per grafica o task generici: usano un’architettura “systolic array” che minimizza i trasferimenti di dati tra memoria e core, riducendo latenza e consumo energetico. Amazon’s Trainium e Inferentia seguono un approccio simile, con NeuronCore per task specifici.
Ecco un confronto sintetico in tabella:
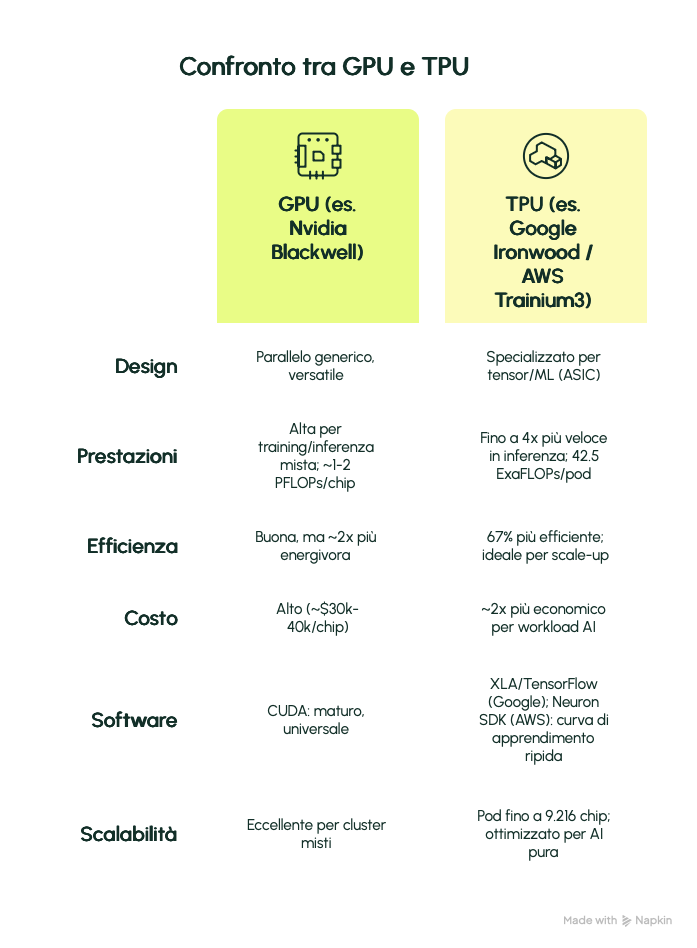
In sintesi, le GPU vincono in flessibilità (es. simulazioni scientifiche), mentre le TPU eccellono in efficienza per AI pura, riducendo costi e emissioni – cruciale in un’era di data center saturi di potenza.
Come hanno fatto le TPU ad emergere come contendenti nel mercato AI?
La storia delle TPU è un viaggio di un decennio, nato dalla necessità interna di Google. Nel 2013, il team Google Brain (guidato da figure come Jeff Dean e Norm Jouppi) si rese conto che l’espansione dell’AI – da AlphaGo a Street View – avrebbe raddoppiato i data center in un anno, schiacciando i costi energetici. Ispirati a tesi del 1978 sui systolic array, svilupparono il primo TPU nel 2015: un chip da 28nm per inferenza, testato in produzione dal 2016 e annunciato a Google I/O.
L’evoluzione è stata rapida: dalla v1 (inferenza pura) alla v4 (2019, pod da 4096 chip), fino a Trillium (v6, 2024) e Ironwood (v7, aprile 2025), con 4.7x le prestazioni della v5e e focus su “thinking models” come Gemini 3. Google ha iterato con Broadcom per la manifattura TSMC, integrando AI nel design (AlphaChip per layout ottimali).
Amazon ha seguito: acquisita Annapurna Labs nel 2015, ha lanciato Inferentia (2018, inferenza) e Trainium (2022, training). Trainium3 (2025) offre 2.52 PFLOPs FP8/chip, con UltraServer da 1 milione di chip – 4x più veloce del predecessore. Entrambe le aziende hanno capitalizzato sul boom GenAI post-ChatGPT: Google ha addestrato Gemini su TPU al 100%, Amazon ha potenziato Anthropic con Trainium2 (mezzo milione di chip nel data center Indiana).
Oggi, le TPU emergono grazie a:
- maturità decennale
- integrazione cloud (GCP/AWS)
- focus su inferenza (70% del mercato AI futuro). Non sono più “interni”: Google vende a Meta (deal da miliardi), Amazon a Hugging Face.
A chi servono le TPU?
Le TPU non sono per tutti: ideali per chi scala AI su larga scala, con workload prevedibili e budget sensibili all’energia. Google le offre via Cloud TPU (da v5e a Ironwood, GA Q4 2025), perfette per training/fine-tuning su Vertex AI o GKE. Utenti: hyperscaler interni (Gemini, AlphaFold), enterprise (ricerca pharma con BioNeMo) e startup (Anthropic: 1M TPU per Claude 4.5).
Amazon’s Trainium/Inferentia via EC2 Trn/Inf: Trainium per training MoE/LLM (Anthropic, ByteDance per video AI), Inferentia per inferenza low-latency (Rufus di Amazon, 2x più veloce in Prime Day). Clienti: Hugging Face (10M+ builder AI), Red Hat (OpenShift AI), Theta Network (edge AI decentralizzato).
In breve:
– Ricercatori/Startup: Economici per prototipi (es. PyTorch su Trainium).
– Enterprise: Healthcare (drug discovery), automotive (autonomous driving), media (sintesi speech).
– Hyperscaler: Diversificazione (Meta da Nvidia a TPU; OpenAI con Broadcom custom).
Non per task non-AI o piccoli setup: qui GPU vincono per versatilità.
Quali sono le prospettive del mercato?
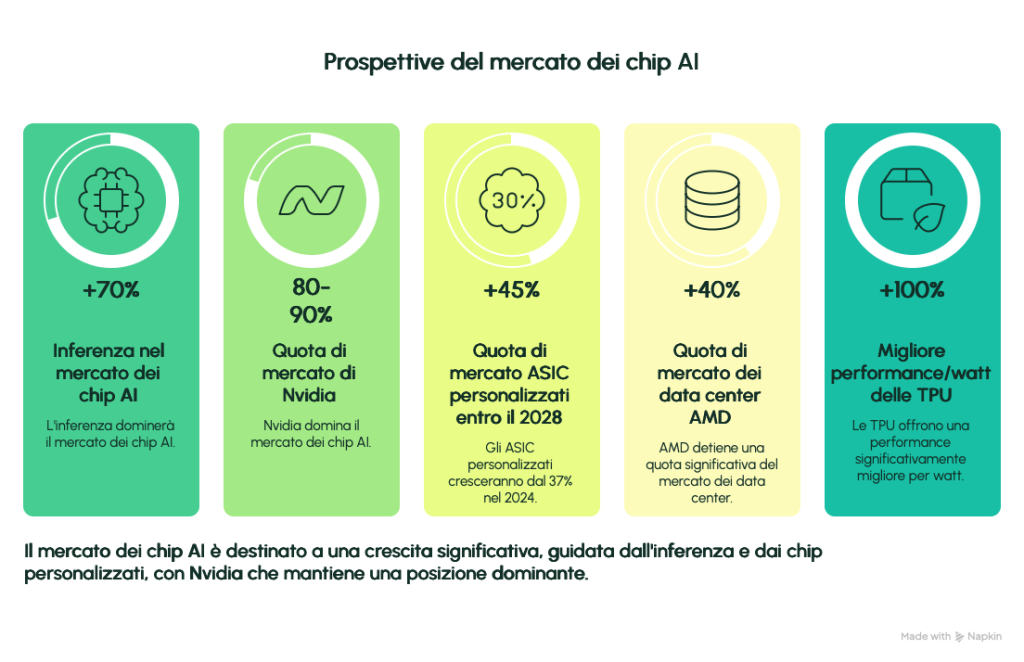
Il mercato AI chip esploderà: da ~$50B nel 2024 a $1T entro 2030 (AMD forecast), con inferenza al 70% (esplosione agentic AI, video gen). Nvidia domina (80-90% share), ma custom ASIC cresceranno: JPMorgan prevede 45% del mercato entro 2028 (da 37% 2024).
Proiezioni 2025-2026:
– Google: $11.25B revenue TPU (2.5M unità, ASP $4.5k); Morgan Stanley: 7M unità/2028 ($13B, +$0.40 EPS Alphabet).
– Amazon: Trainium3 da Q3 2025, $1B revenue Alchip; 30-40% better price/performance vs GPU.
– Totale: $290-300B capex data center AI (Meta/Amazon/Google 200B); AMD $15B data center (40% share CPU server).
Tendenze: Shift a edge/inferenza (Trainium4 2026 con Nvidia compatibilità); geopolitica spinge diversificazione (Cina ispeziona Nvidia). Opportunità: Sostenibilità (TPU 100% better perf/watt) e token economics (Trainium3 ottimizza costi per query).
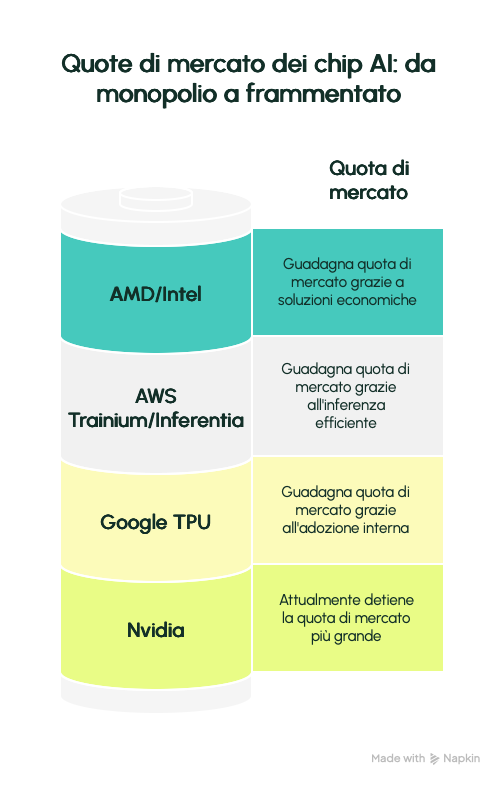
Rischi competitivi per Nvidia e quote di mercato possibili per i competitor
Nvidia è vulnerabile: il 78-82% margine lordo deriva dal monopolio, ma custom chip erodono. Google/Amazon riducono dipendenza (Google: 100% Gemini su TPU; Amazon: 50% savings vs GPU). Meta’s deal TPU (2026 leasing, 2027 on-prem) potrebbe spostare 10% share Nvidia, +$10B Google Cloud.
Rischi per Nvidia:
– Market Share Loss: Da 80-90% a 60-70% entro 2027 (BofA: graduale, ma inevitabile; AMD/Intel +15-20%).
– Pricing Pressure: TPU 2x cheaper; Trainium 25-50% cost edge – forza sconti, comprime margini a 70%.
– Ecosystem Lock-in: CUDA vs XLA/Neuron: startup esitano (riscrittura codice), ma hyperscaler migrano (Anthropic diversifica da Trainium a TPU).
– Supply/Geopolitica: Dipendenza TSMC (70% foundry); Cina blocca H20/H100, +$5-10B hit 2025.
– Inference Shift: 70% mercato futuro; TPU/Ironwood 4x faster qui, vs GPU generali.
Quote possibili:
– Google TPU: 10-15% entro 2027 (da 0% external; Meta/Anthropic spingono).
– AWS Trainium/Inferentia: 8-12% (30% share inference; Hugging Face/Red Hat).
– AMD/Intel: 15-20% combinato (AMD MI450 2026; Intel Gaudi3 cost-effective).
Nvidia risponde: Blackwell Ultra (288GB HBM, 50% boost FP4); Dynamo framework open-source. Ma il mercato si frammenta: “Non è zero-sum” (Nvidia CEO), ma diversificazione è chiave. Per investitori, monitora Q4 2025 earnings: se capex AI cala 10%, share loss accelera.
Conclusione
i lanci TPU segnano l’inizio di un’era multipolare in AI hardware. Nvidia resta leader, ma Google/Amazon forzano innovazione e prezzi più bassi – beneficio per l’ecosistema. Per il tuo business, valuta un proof-of-concept su GCP/AWS: l’efficienza potrebbe trasformare i costi AI.





